Audio Reasoning Challenge
Interspeech 2026
-
2026-02-16📊 Final results are now available on the Leaderboard page! Check out the benchmark and scripts, and read the challenge report.
-
2026-01-01🎁 To encourage creative approaches in audio reasoning, we are thrilled to announce that the organizing committee will select one team for the Best Innovative Award and a NVIDIA RTX 5070 will be granted.
-
2026-01-01🔥 Leaderboard (Single Model Track) and (Agent Track) goes live! We will send leaderboard registration instructions to teams who have registered (link) here.
-
2025-12-31Please refer to the Leaderboard page for the detailed evaluation methods.
-
2025-12-03Please refer to the FAQs page for the frequently asked questions.
-
2025-12-01Please join our slack and WeChat group for real-time communication in the Contact section.
-
2025-12-01Registration (link) for teams is open now! The deadline for registration is 2026-01-15. Register early to get latest updates.
-
2025-12-01Baselines (link) released!
-
2025-11-25Website goes live!
Introduction
Understanding and reasoning about sound is a fundamental aspect of human intelligence. From spoken conversations and musical compositions to subtle environmental cues, humans can not only perceive a wide variety of auditory signals but also interpret their meanings, draw inferences, and make decisions in complex acoustic scenarios. Replicating this capability in artificial systems has long been a key goal of AI research.
Recent progress in Large Language Models (LLMs), combined with advances in audio processing, has given rise to Large Audio Language Models (LALMs)[1-10]. Leveraging large-scale multimodal training and sophisticated architectures, LALMs have achieved impressive results in audio perception tasks such as automatic speech recognition (ASR) and automated audio captioning (AAC). Beyond perception, several recent works have made initial attempts to bring explicit Chain-of-Thought (CoT) reasoning into the audio domain, including Audio-CoT[11], Audio-Reasoner[12], Qwen3-Omni-Thinking[13], and Audio Flamingo 3[14], demonstrating improved reasoning performance by integrating advanced cross-modal thinking strategies.
However, despite these advances, current LALMs still exhibit limited and unstable reasoning capabilities. Even on established reasoning benchmarks like MMAR[15] and MMAU-Pro[16], they often produce direct answers without presenting the underlying reasoning process, or show inconsistent performance across tasks and inputs. This lack of transparent and reliable reasoning limits interpretability, trustworthiness, and the potential to generalize reasoning ability to unseen audio scenarios.
Challenge Goals
To address this gap, we have enriched the MMAR benchmark with manually labeled CoT annotations and explicit reasoning cues, enabling systematic evaluation of LALMs in reasoning-intensive tasks. Building on this resource, we propose the Audio Reasoning Challenge at Interspeech 2026, designed to push LALMs beyond surface-level response accuracy toward robust, interpretable reasoning.
Our evaluation framework adopts a stricter criterion: a prediction is considered correct only if both the reasoning path and the final answer are accurate, ensuring that models are rewarded for genuine, logically consistent thought processes. The challenge features two complementary tracks:
- Single Model Track: Participants can use open-source data to post-train open-source models, focusing on intrinsic model reasoning capabilities.
- Agent Track: Participants can use open-source models to build an agent system or pipeline without human-in-the-loop, emphasizing system-level orchestration and tool use.
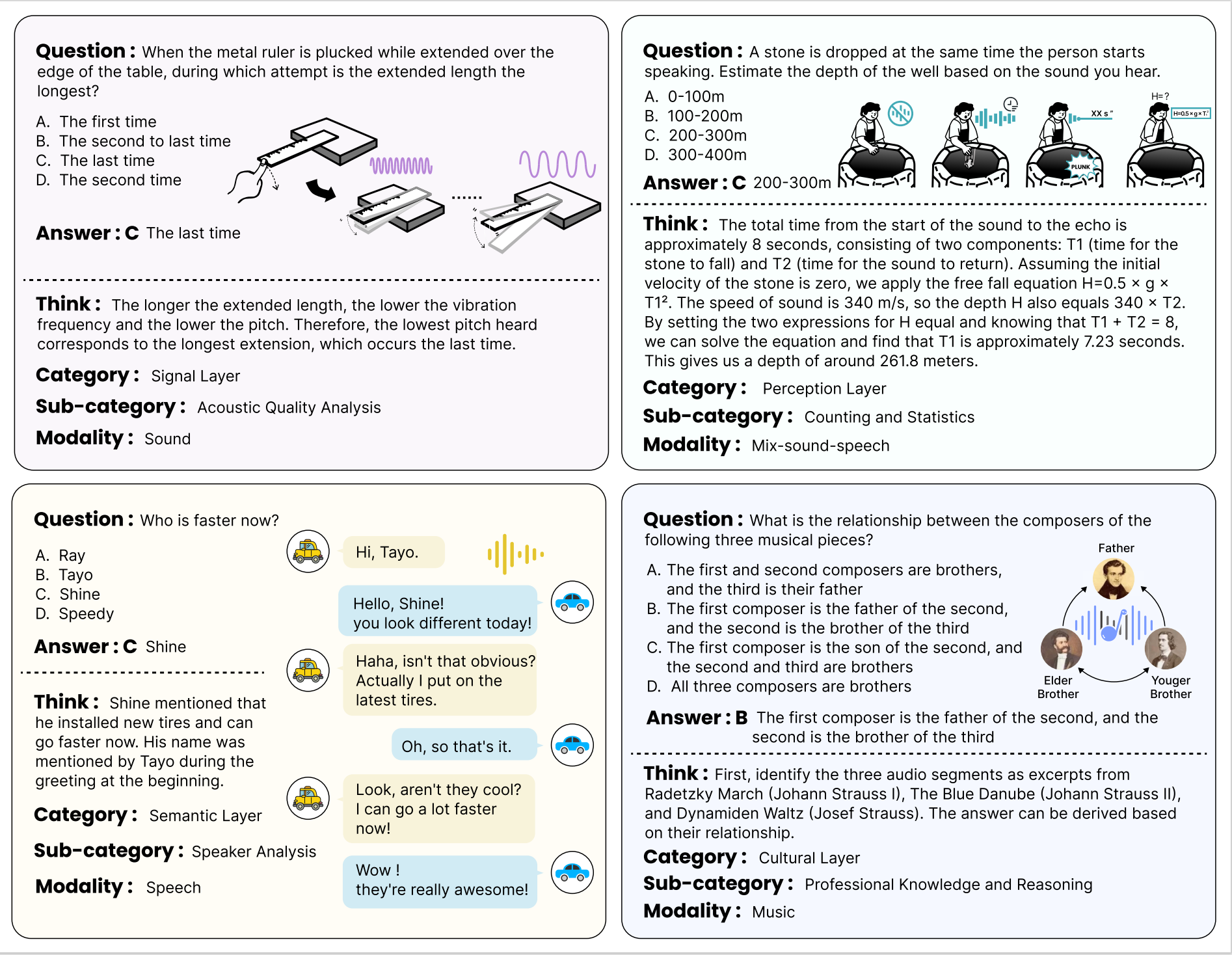
Examples (with CoT annotated) from the MMAR benchmark, spanning audio, speech, music, and their mix, and illustrating challenges at the signal, perceptual, semantic, and cultural levels.
Challenge Tracks
Track 1: Single Model Track
Participants build a single, end-to-end Audio–Language Model that consumes the audio and produces (i) a Chain-of-Thought (CoT) reasoning trace and (ii) a final answer. Systems must perform intrinsic reasoning within one forward without delegating to external tools, APIs, search engines, or separate controllers. The goal is to isolate model-internal reasoning quality under our strict criterion: a prediction is counted correct only if both the CoT and the final answer are validated.
Track 2: Agent Track
Participants design an audio reasoning agent that may orchestrate multiple open-source models and tools (e.g., ASR, separation, beat/onset tracking, captioners, planners) to produce a CoT path and a final answer. This track evaluates system-level reasoning: planning, tool selection, and self-checking under the same strict correctness criterion. The emphasis is on transparent trajectories that reveal how intermediate audio analyses contribute to decisions, moving beyond answer-only pipelines.
Benchmark and Evaluation Protocol
Benchmark
All submissions will be evaluated on the updated version of MMAR benchmark, a 1,000-item dataset designed for deep audio reasoning across speech, sound, music, and mixed-modality scenarios. Each sample contains audio, a question, a ground-truth answer, and a newly annotated CoT rationale.
Submission Format
Participants must submit a JSONL file to the online leaderboard, where each line contains:
{
"id": "<sample_id>",
"thinking_prediction": "<model_or_agent_generated_CoT>",
"answer_prediction": "<final_prediction>"
}
The leaderboard will automatically compute all metrics and rank systems by the primary score.
Evaluation Metrics
- Answer Correctness: If the
answer_predictionis incorrect, the score is 0. - Reasoning Quality: If the answer is correct, an LLM-as-a-judge evaluates the
thinking_predictionon a scale of 0.2 to 1.0 (in 0.2 increments). - Stability Mechanism: To account for variance, each submission is calculated based on 5 independent evaluation runs. The final score for each metric will be the mean of the 3 middle runs, effectively discarding the highest and lowest results.
Registration and Leaderboard
Registration for the leaderboard and Google Form submission are required. Refer to the Leaderboard tab for more details.
Paper submission
Participants can submit a paper describing the submitted model or system to the Interspeech 2026. Paper submission is independent of the leaderboard ranking. Submissions describing the competition systems or reporting research results for audio reasoningng equally welcome. The submitted papers will go through the same review process as the regular papers and will be indexed and included in the ISCA archive.
Contact
We have a Slack channel and a WeChat group for real-time communication. Please send an email if you have any private questions.


Organizers












References
Follow us on GitHub for updates: @Audio-Reasoning-Challenge